Use Sharding to Reduce Mutex Contention
Associative data structures are extremely prevalent in all types of software. They are the underlying storage behind hash maps, sets, and most kinds of caches. These data structures are also notoriously hard to synchronize such that multiple threads can read and write to them in an efficient manner without inducing race conditions.
Single Mutex
One common solution is to use a single mutex which guards the entire data structure.
class ThreadSafeHashMap {
Mutex mu;
// Not thread safe.
HashMap map;
void put(key, value) {
mu.lock();
map.put(key, value);
mu.unlock();
}
...
}
The issue with this is that when multiple threads try to perform operations at the same time, the mutex essentially serializes them. This creates high mutex contention and throws away all performance gains provided from using multiple threads.
Granular Locking
On the other end of the spectrum, one could implement their own hash map which natively supports multi threaded operations via granular locking. That is, leveraging knowledge of the underlying implementation such that you can use multiple mutexes which each cover the smallest unit possible. For example when implementing a thread safe hash map one might use a single mutex per hash node and carefully coordinate the locking.

While this provides the highest level of performance, this type of code is difficult to write and even more difficult to verify its correctness. Additionally the work done on one data structure (e.g. a hash map) may not (and very likely will not) translate to another (e.g. a binary tree).
Sharding
The sweet spot between these two techniques is known as sharding. The idea is to to split the data structure into shards and assign each key to a shard using a uniformly distributed hash function. Each shard is mutex protected, and therefore operations only need to lock one shard of the data structure, not the entire thing.
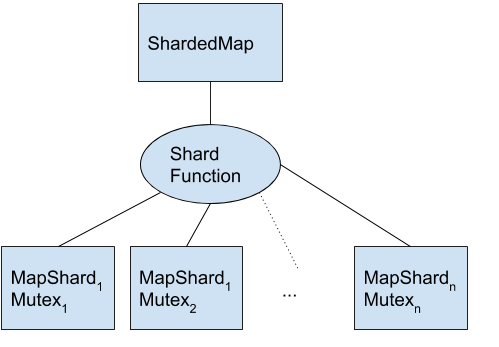
This approach will still reduce lock contention significantly compared to the single mutex approach, and is trivial to implement.
class ShardedMap {
class MapShard {
Mutex mu;
HashMap map;
}
vector<MapShard> shards;
// Note that n_shards should generally be the number of threads accessing the
// map. Anything greater than that will not provide any benefit.
ShardedMap(n_shards): shards(n_shards) {}
void put(key, value) {
map_shard = shards[shard_function(key)]
map_shard.mu.lock()
map_shard.put(key, value)
map_shard.mu.unlock()
}
}
No custom logic is required, the sharded map is just a thin wrapper class around the underlying data structure. This same logic can be applied to most associative data structures and just work out of the box.
Caveats
Extra Memory
Sharded data structures will use slightly more memory than their non-sharded counterparts. This overhead comes from the constant memory allocated for each shard (e.g. size, data pointers, etc) and the memory overhead of the vector. This extra memory overhead is likely to be negligible, but worth mentioning.
Hot Keys
Sharded data structures are somewhat vulnerable to hot keys. I.e. a single key which is frequently operated on. In this case there will be high contention on the shard for which this key belongs to. This can be mitigated by introducing a non-determinstic sharding function which places hot keys in more than 1 shard. This solution does complicate things though, and introduces a probabilistic component to the data structure (e.g. look ups may result in the key not being found, when in fact it is actually in another shard. This trade off is generally acceptable in cache scenarios, where failed look ups just result in the key being re-populated).